Paper Link: AutoDIAL: Automatic DomaIn Alignment Layers (thecvf.com)
Supplementary Material: Carlucci_AutoDIAL_Automatic_DomaIn_ICCV_2017_supplemental.pdf (thecvf.com)
Code Link: https://github.com/ducksoup/autodial
Key Elements
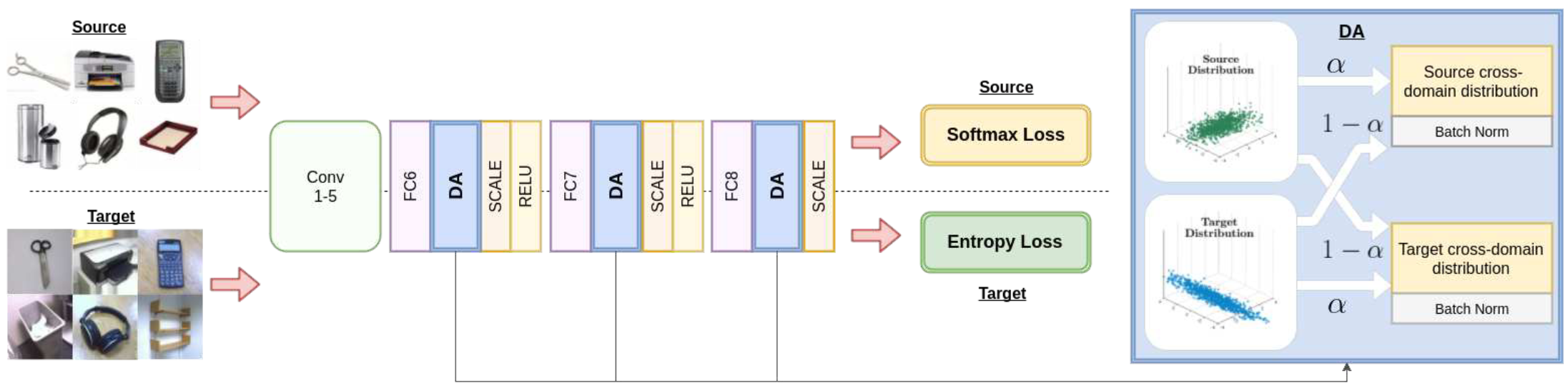
- Softmax loss on source samples
- Entropy minimizaiton on target samples
- DA-layers to adapt the features
DA Layer
-
The DA layer used for source data and the DA layer used for target data is probably going to be different, because there is a large probability that the distributions of source and target are different.
-
Every DA layer will have an $\alpha$ parameter, used for determining how deeply the DA layer will adapt to its input data.
-
DA layer specifics:
-
Let’s first construct two new distributions:
$q_\alpha^{st} = \alpha q^s + (1 - \alpha) q^t$
$q_\alpha^{ts} = \alpha q^t + (1 - \alpha) q^s$
where: $\alpha \in [0.5,1]$
We can se $q_\alpha^{st}$ as the source distribution being contaminated by the target distribution and vice versa.
-
And according to the calculation process of BN layer, we can directly write out the output expression for DA layer:
$DA(x_s ; \alpha) = \frac {x_s - \mu_{st,\alpha}} {\sqrt {\epsilon + \sigma^2_{st,\alpha}}}$
$DA(x_t ; \alpha) = \frac {x_t - \mu_{ts,\alpha}} {\sqrt {\epsilon + \sigma^2_{ts,\alpha}}}$
-
$\alpha$ will be learned during training process. It directly depends how deeply the adaptation level of the DA layer currently is.
$\alpha=0.5$ means no adaptation at all. In other words, current DA layer makes the same transformation for data from source and target domains.
$\alpha=1$ means deeply adaptation
-
$q^{st}_\alpha$
and $q^{ts}_\alpha$ is definitely unmeasurable, because source and target distributions are unmeasurable. So how did the authors calculate the mean and variance for the two mixed distributions?
- I’m having trouble with understanding the training process in the original paper.
- Can I try incorporate DA Layer or AdaBN into DAN? With some statistical improvement.
Zenvi
One Just Vegetable Chick


Comments