Paper Link: Model Adaptation: Unsupervised Domain Adaptation Without Source Data (thecvf.com)
Key Elements
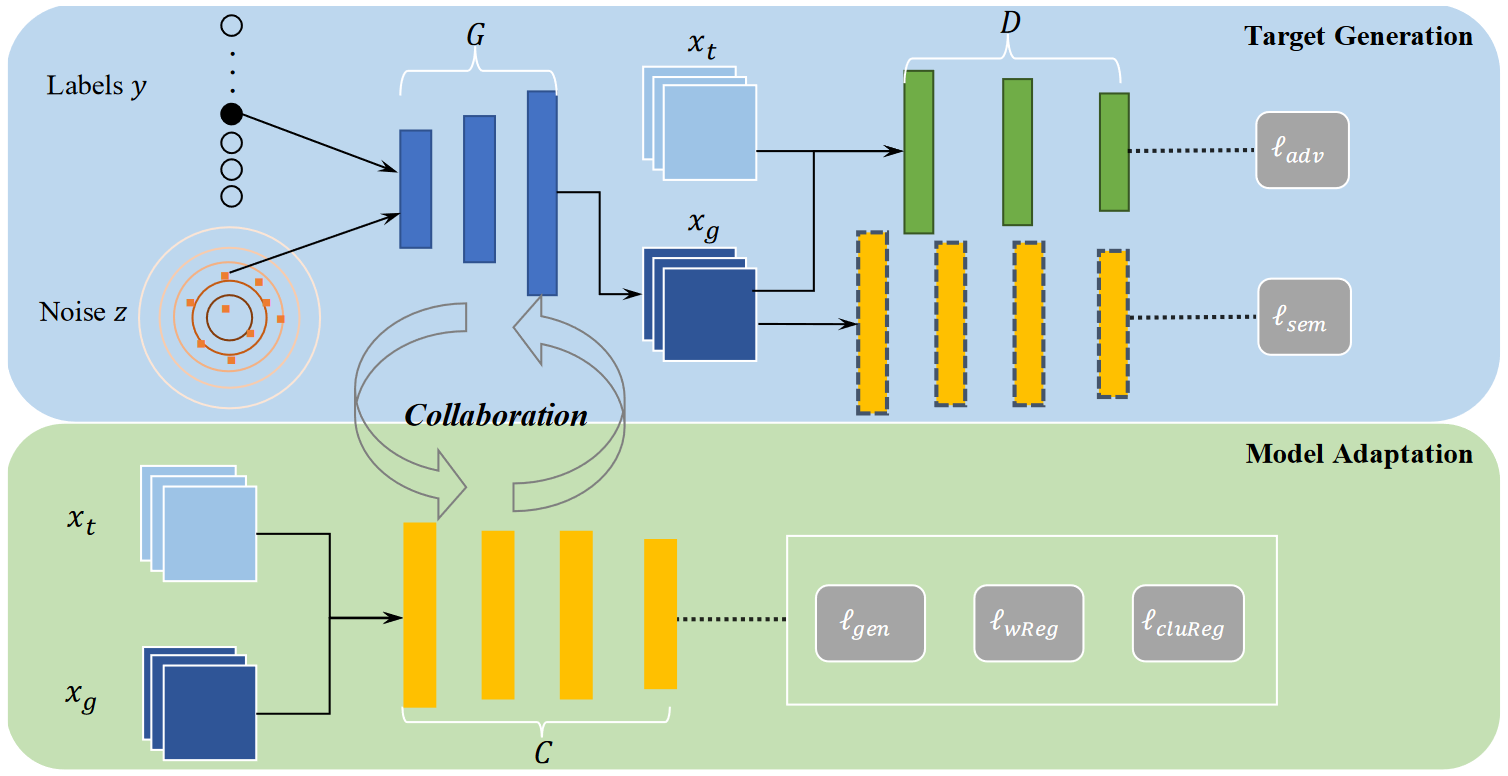
-
Target Generation:
-
Collaborative Class Conditional GAN (3CGAN)
-
Domain Discriminator D:
$ \max_{\theta_D} \mathbb E_{x_t \sim D_t } [log D(x_t)] + \mathbb E_{y,z}[log(1-D(G(y,z)))]$ Which is try to tell whether its inputs are original target samples or generated target sample
-
Generator G:
$l_{adv}(G)=\mathbb E_{y,z}[logD(1-G(y,z))]$ $\min_{\theta_G}l_{adv}+\lambda_sl_{sem}$ Which is trying to confuse the Domain Discriminator D
And minimize the cross-entropy loss
-
Fixed Predictor C (Pretrained on source domain):
$l_{sem}(G)=\mathbb E_{y,z}[-ylog_{p_{\theta_C}}(G(y,z))]$ Which is there to check whether the generated samples... read more
-
-


Comments